OCR (光学文字認識)
紙の文書をスキャンして電子形式でコンピューターにアーカイブすると、ドキュメントを整理しやすくなり、ストレージ スペースを大幅に節約できます。ただし、特定の単語や語句に関連する情報を見つけたい場合は、すべてのファイルを開いてドキュメントを読む必要があります。OCR (光学文字認識) 機能を使用すると、スキャンしたドキュメントのテキストが検索可能になり、コンテンツを簡単に検索または編集できます。
OCR は、印刷されたテキストの画像を機械読み取り、検索、編集可能なテキストに変換します。その後テキスト マークアップ ツールを使用してコメントを付けたり、ドキュメント内のテキストに変更を加えたりすることができます。
単一ファイルで OCR を実行
OCR を実行して、スキャンしたドキュメントのテキストを検索および編集可能に変換し、レビューおよびコメント ツールでコメントを追加またはテキストをマークアップできます。OCR は、レンダリング可能なテキスト (画像レイヤーの上に配置されたコンピューター生成テキスト) を含むページでは実行できないことに注意してください。
現在のファイルで OCR を実行
-
Right PDF Editor で OCR を実行する PDF を開きます。
-
[アドバンス] > [テキストの認識] > [OCR] を選択し、オプションから [現在のファイル] を選択します。
を選択し、オプションから [現在のファイル] を選択します。
-
[OCR テキスト認識] ダイアログ ボックスで、必要に応じて OCR 設定を調整します。
-
ページ範囲 すべてのページ、現在のページ、または選択したページを認識するように選択します。
-
ページ傾きの自動補正 このチェックボックスをオンにすると、Right PDF Editor はページのゆがみを自動的に調整します。
-
PDF の種類 作成する PDF の種類を指定します。
-
検索可能 イメージ テキストを検索可能にします。
-
検索および編集可能 イメージ テキストを検索および編集可能なテキストに変換します。
-
MRC PDF ドキュメント MRC を使用して画像を圧縮します。
-
検索可能な MRC MRC を使用して画像を圧縮し、テキストを検索可能にします。
-
MRC 圧縮 スライドバーを使用して圧縮レベルを設定します。圧縮率が高いほど、ファイルが小さくなり、品質が低下します。MRC は、テキスト要素を画像や背景から分離し、各要素に最適な圧縮を適用します。
-
認識する言語 文字を認識するために使用する OCR エンジンの言語を選択します。OCR の精度を最大限に高めるには、ドキュメントに含まれる言語のみを選択します。複数の言語を選択する場合は、次の制限に注意してください。
-
言語の自動検出 オンにすると、 Right PDF Editor は各ページに適した言語を検出して適用します。

-
[OK] をクリックします。
複数のファイルで OCR を実行
-
[アドバンス] > [テキストの認識] > [OCR] を選択し、オプションから [複数のファイル] を選択します。
を選択し、オプションから [複数のファイル] を選択します。
-
[OCR テキスト認識] ダイアログ ボックスで、OCR を実行するファイルを参照して選択し、[OK] をクリックします。
-
ファイルを追加... Ctrl キーを押しながらクリックして複数ファイルを選択し、[開く] をクリックします。選択したファイルがファイル リストに追加されます。
-
フォルダーを追加... フォルダーを選択して [OK] をクリックします。選択したフォルダー内のすべてのファイルがファイル リストに追加されます。
-
削除 1つのファイルを選択するか、Ctrl キーを押しながらクリックして複数のファイルを選択し、[削除] をクリックします。選択したファイルはファイル リストから削除されます。
-
現在開いているファイルを含める オンにすると、現在開いているすべての PDF がファイル リストに追加されます。
-
[出力オプション] ダイアログ ボックスで、出力ファイルのターゲット フォルダーとファイル名の設定を指定し、[OK] をクリックします。
-
ターゲット フォルダー 出力 PDF を元と同じフォルダーに保存するか、指定した別のフォルダーに保存するかを選択します。
-
ファイル名の指定 元のファイル名で保存するか、元のファイル名に接頭辞/接尾辞を挿入するかを選択します。元のファイル名に接頭辞/接尾辞を挿入するには、[元のファイル名に追加] を選択し、[前に挿入] と [後に挿入] ボックスにテキストを入力して、出力ファイルに「挿入されたテキスト+元のファイル名+挿入されたテキスト.pdf」の形式で名前が付けられるようにします。[元のファイル名を維持] を選択した場合、[既存のファイルを上書き] をオンにして、出力 PDF ファイルが元のファイルを上書きするようにする必要があります。
-
[OCR テキスト認識-設定] ダイアログ ボックスで、次の設定を調整します。
-
ページ傾きの自動補正 このチェックボックスをオンにすると、Right PDF Editor はページのゆがみを自動的に調整します。
-
PDF の種類 作成する PDF の種類を指定します。
-
検索可能 イメージ テキストを検索可能にします。
-
検索および編集可能 イメージ テキストを検索および編集可能なテキストに変換します。
-
MRC PDF ドキュメント MRC を使用して画像を圧縮します。
-
検索可能な MRC MRC を使用して画像を圧縮し、テキストを検索可能にします。
-
MRC 圧縮 スライドバーを使用して圧縮レベルを設定します。圧縮率が高いほど、ファイルが小さくなり、品質が低下します。MRC は、テキスト要素を画像や背景から分離し、各要素に最適な圧縮を適用します。
-
認識する言語 文字を認識するために使用する OCR エンジンの言語を選択します。OCR の精度を最大限に高めるには、ドキュメントに含まれる言語のみを選択します。複数の言語を選択する場合は、次の制限に注意してください。
-
言語の自動検出 オンにすると、 Right PDF Editor は各ページに適した言語を検出して適用します。
-
[OK] をクリックします。ページにレンダリング可能なテキストが含まれている場合、OCR はコンピューターで生成されたテキストを認識しないことを示すメッセージが表示されます。

不明テキストの修正
[不明テキストを検索] 機能は、潜在できな認識ミスを見つけて、テキストを修正するオプションを提供します。スキャンしたドキュメントのテキストを検索可能にした後に使用できます。したがって、スキャンされた元のドキュメントのテキストが鮮明であるほど、発生する不明テキストは少なくなります。
不明テキストの検索および置換
-
OCR を実行するスキャンした PDF を開きます。必ずコピーを作成して、コピーのみで OCR を実行してください。
-
[アドバンス] > [テキストの認識] > [OCR] を選択し、必要に応じてメニューから [現在のファイル] または [複数のファイル] を選択します。次に、テキストを検索可能にするか、検索および編集可能にするかを指定し、[OK] をクリックします。詳細については、現在のファイルで OCR を実行を参照してください。
を選択し、必要に応じてメニューから [現在のファイル] または [複数のファイル] を選択します。次に、テキストを検索可能にするか、検索および編集可能にするかを指定し、[OK] をクリックします。詳細については、現在のファイルで OCR を実行を参照してください。
注意: 不明テキストを検索機能は、スキャンしたドキュメントのテキストを検索可能に変換した場合にのみ使用できます。テキストを検索可能にしながら、元のスキャンしたドキュメントの外観を維持します。
-
これでドキュメントのテキストが検索可能になり、[不明テキストを検索] を使用して OCR エンジンが正しく認識しなかったものがあるかどうか確認し、修正を行うことができます。[アドバンス] > [テキストの認識] > [不明テキストを検索 ] を選択し、必要に応じて次のいずれかを選択します。
を使用して OCR エンジンが正しく認識しなかったものがあるかどうか確認し、修正を行うことができます。[アドバンス] > [テキストの認識] > [不明テキストを検索 ] を選択し、必要に応じて次のいずれかを選択します。
-
最初の OCR の不明テキスト 最初の不明テキストを検索して表示します。[エレメントの検索] ダイアログ ボックスで、[検索] ボタンをクリックすると、[エレメントの検索] ダイアログ ボックスに最初の不明テキストが表示されます。
-
すべての OCR の不明テキスト すべての不明テキストを検索して表示します。ページ上のすべての不明テキストの周囲にボックスが表示されます。不明テキストをダブルクリックすると、[エレメントの検索] ダイアログ ボックスに不明テキストが表示されます。

-
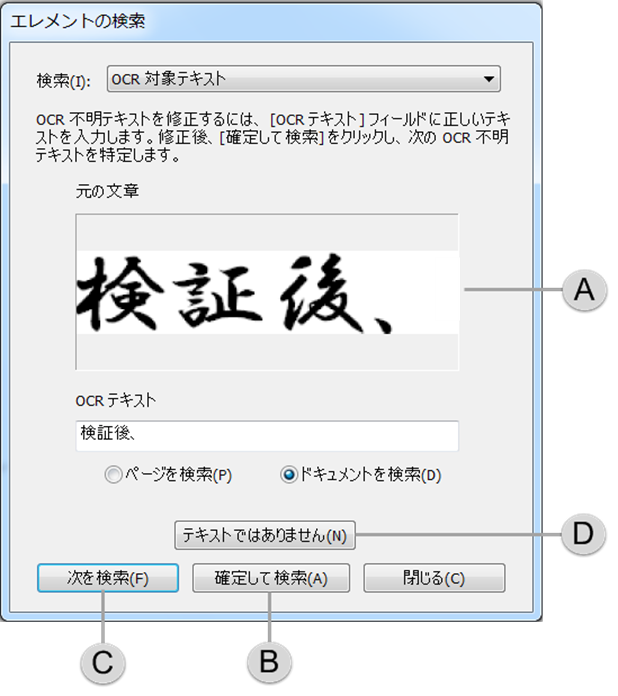
[エレメントの検索] ダイアログ ボックスには元の文書のテキストと、OCR によるテキストの両方が表示されます。[OCR テキスト] ボックスのテキストと、[元の文書] ボックス (A) のテキストを比較します。次のオプションを使用して不明テキストを処理します。
-
[確定して検索] (B) をクリックすると、正しい認識と処理して次の不明テキストに移動します。OCR エンジンの認識結果が正しくない場合は、[OCR テキスト] ボックスに新しいテキストを入力し、[確定して検索] をクリックして修正されたテキストに置き換えます。
-
[次を検索] (C) をクリックすると、次の不明テキストに移動します。
-
不明テキストが誤ってテキストとして認識されている場合は、[テキストではありません] (D)をクリックします。